AI Document Review: Why 'Looks Good' Isn't Good Enough
Sidenote Team

AI generates fast. It doesn't always get it right. Here's why structured review catches what casual checking misses.
AI is fast at generating content. It's less reliable at getting it right the first time. A 2024 study by Vellum found that GPT-4 outputs required human editing in 78% of professional use cases. Factual accuracy, tone, and formatting were the top correction categories.
Most teams skip the structured review step. They skim the output, think it looks acceptable, and ship it. That's when the problems start.
The Cost of Skipping Review
Bad AI content erodes trust. Not because it's written by AI, but because it slips through without human verification. A financial services company publishing a report with hallucinated data. A product team launching a help center article with outdated steps. A marketing team sending customer emails that miss the brand voice entirely.
These aren't edge cases. They happen because review was treated as a formality instead of a gate.
The damage compounds. One published error creates rework. Corrections take time. Customer support fielding questions about wrong information. Internal teams scrambling to fix inconsistencies. The cost of fixing published mistakes is always higher than catching them before they go live.
Beyond the operational cost, there's brand erosion. People notice when documentation is wrong. They notice when tone doesn't match your brand. They remember the company that sent out content with factual errors. That memory is harder to fix than the content itself.
Why Casual Review Misses Problems
"Looks good" review has three blind spots.
Skimming bias. When you read quickly for overall impression, your brain fills in gaps. You see what you expect to see, not what's actually on the page. Studies in cognitive psychology show reviewers catch 50–60% of errors in skimmed content, compared to 85%+ in structured review (Pashler, H. et al., 2005). Your eye slides over a factual claim you didn't verify. A formatting inconsistency you didn't register. An awkward sentence you read the way you meant it to be read, not the way it's written.
Format over substance. Good visual design or proper structure can mask bad content. A well-formatted report with incorrect information looks more credible than an ugly report with correct information. Your brain trusts the package more than the contents. AI outputs are often polished on the surface. The errors are in the details.
Reviewers don't know what to look for. Without a system for categorizing problems, reviewers miss entire categories of issues. One person focuses on grammar. Another on formatting. Nobody notices the outdated reference or the tone that clashes with the brand. Structured feedback frameworks catch what scattered attention misses.
Casual review trades thoroughness for speed. For low-stakes content, that's fine. For anything that goes public or affects decisions, it's a risk.
| Dimension | Casual review | Structured review |
|---|---|---|
| Error detection rate | 50–60% of issues caught | 85%+ with categorized review passes |
| Feedback format | Vague — "this section is weak" | Anchored to specific text with category tags |
| Pattern visibility | Same issues repeat unnoticed across drafts | Categories surface systemic trends |
| AI actionability | Agent guesses what to change | Agent targets exact flagged passages as structured data |
| Version tracking | Each review pass starts from scratch | Annotations carry forward, builds on previous rounds |
| Time cost | Fast first pass, expensive rework downstream | Slower first pass, compounds efficiency over iterations |
| Trust risk | Errors reach audience, erode brand credibility | Problems caught before publication |
What Structured Review Actually Means
Structured review isn't bureaucracy. It's specificity.
Annotations anchored to text instead of vague feedback. Not "this section is weak" but "the third paragraph contradicts the opening claim about market size." Not "tone is off" but "this line sounds promotional when the brand voice calls for matter-of-fact." Not "fix this" but "this data point needs a 2024 source, not 2021."
Categorized feedback so patterns emerge. "Factual accuracy" as a category. "Brand voice" as a category. "Formatting consistency" as a category. When feedback is sorted this way, you see what types of errors cluster. Maybe factual accuracy is the biggest problem. Maybe AI is nailing the facts but missing tone. Patterns inform the next iteration.
Version tracking so you see what changed. When reviewers markup an AI draft and the AI regenerates, you don't start from zero. You see the previous round of annotations. You see what was fixed. You see what new issues appeared. This feedback loop compounds learning.
Sidenote enables this workflow. You upload the AI-generated document. Reviewers annotate inline, categorizing feedback. The AI agent retrieves the annotations as structured data. It regenerates based on specific, anchored feedback. The next version comes back with improvements targeting the actual problems, not guesses about what might be wrong.
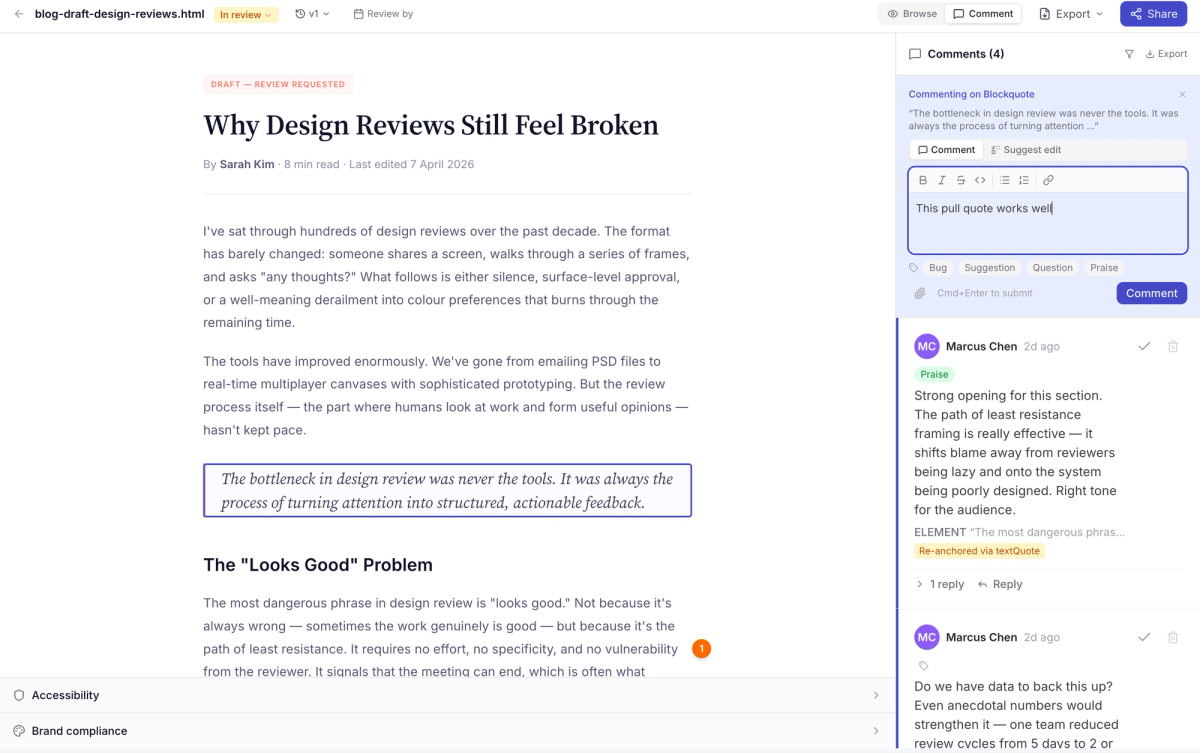
The whole loop is traceable. Every piece of feedback connects to specific text. Every iteration improves against known issues. Every version is archived. You can see the path from rough AI output to publication-ready document.
Real Examples of What Gets Missed
Hallucinated facts slip through casual review. A tech company's AI-generated case study claimed a customer achieved "47% efficiency gains from our platform." The customer never measured that metric. The review process skimmed over the claim. It shipped. The customer saw it and corrected the company publicly.
Tone drift happens quietly. An internal communications team uses AI to draft an employee announcement. The AI sounds corporate and formal. The company culture is irreverent and direct. A quick review nods it through because the information is correct. It ships. Employees notice the tone doesn't sound like the company. It reads as outsourced. That's a signal problem, not a content problem.
Outdated information doesn't announce itself. An AI generates a help article about a feature. Six months later, that feature changes. The document never gets updated because it's not flagged as time-sensitive. A customer finds the old version and wastes an hour following outdated steps. That's a failure of structure, not content.
Brand voice inconsistency compounds across documents. The AI system generates marketing emails with conversational warmth. Product documentation comes out matter-of-fact. Customer success content is formal. Each piece individually sounds acceptable. Together, they signal an organization without a unified voice. Structured feedback that identifies voice drift catches this before publishing.
How the Feedback Loop Improves Output
One round of annotation doesn't create perfect content. The improvement happens in iteration.
AI responds better to structured feedback than to vague notes. Tell it to "improve the tone," and you get a rewrite that might miss the actual problem. Mark the specific sentence, tag it as "too promotional," and annotate why, and the next version targets that exact issue. The feedback is actionable.
{
"feedback": [
{
"selection": "47% efficiency gains from our platform",
"category": "factual_accuracy",
"comment": "Customer never reported this metric. Replace with verified outcome or remove."
},
{
"selection": "industry-leading, world-class platform",
"category": "brand_voice",
"comment": "Too promotional. Brand voice is matter-of-fact and specific."
}
]
}Each iteration compounds learning. The second draft improves against the first round of feedback. If factual accuracy was the main issue, the AI can prioritize fact-checking and source verification on regeneration. If tone was the issue, it recalibrates voice for the second pass. The system learns what matters most.
Reviewers waste less energy on the same problems. If a document came back with the same error twice, you'd notice immediately. That's feedback pressure to focus on that category. Without tracking, the same error can slip through multiple rounds because you don't see the pattern.
The cost of review decreases over time. Early iterations might need significant feedback. By round three or four, reviewers are catching edge cases, not fundamental issues. The efficiency compounds as the system improves. Contrast that with casual review, where every pass is starting from scratch.
FAQ
How long does structured review actually take?
The first round takes longer because reviewers are learning the document and the feedback system. Subsequent rounds are faster because the document improves and feedback is more targeted. A typical cycle is 15–20 minutes per round for a 3,000-word document, including AI regeneration time.
Does this work for all types of AI content?
It works best for content that goes public or affects decisions. Blog posts, documentation, customer communications, reports. It's less critical for brainstorms or internal drafts where accuracy is less high-stakes. The structured approach pays for itself once you're past the idea stage.
What if the feedback contradicts itself?
Structured review surfaces contradictions because they're anchored to specific text. If one reviewer marks a sentence as "too formal" and another marks it as "not formal enough," that's visible. You can see both annotations and resolve the conflict. Casual review hides contradictions because feedback is vague.
Can AI agents actually use this feedback to improve?
Yes. Agents connected via MCP retrieve feedback as structured data. They see categorized annotations with specific text references. This lets them regenerate with precision instead of guessing what needs to change. See how the feedback loop works with AI agents for details.
What happens to rejected content?
Nothing goes to trash. Every version is tracked. If you reject a direction and want to revert, the previous version is there. If you realize three iterations in that an earlier draft was on the right track, you can see it. Version history protects against the false start problem where you abandon good direction halfway through.
The Shift From Speed to Verification
The promise of AI is speed. Generate, ship, move on. The reality is that speed without verification creates more work, not less. A botched customer communication requires correction. A published error requires retraction. A trust loss requires rebuilding.
Structured review isn't slow. It's the opposite. It catches problems before they cost more to fix. It lets AI improve with each iteration. It creates a feedback trail so you understand what worked and what didn't.
The teams winning with AI aren't the fastest at generating. They're the most disciplined about review.
Want to see how structured review works in practice? Sidenote lets your team annotate AI documents inline, then feeds that feedback back to your AI agents as structured data. No special setup. Just upload, review, improve, repeat.
New to Sidenote? Read what it is and how it works, or see how AI agents use MCP to close the feedback loop.